-
 Circular Dependencies vermeidenHalte Dich an eine strikte Architektur wie die «Clean Architecture» um zirkuläre Abhängigkeiten zu vermeiden.
Circular Dependencies vermeidenHalte Dich an eine strikte Architektur wie die «Clean Architecture» um zirkuläre Abhängigkeiten zu vermeiden. -
Interfaces in Go sind etwas anders als gewohntMache Dich mit Interfaces in Go vertraut. Anders als in anderen Sprachen sind diese «implizit» und werden nur sehr spärlich eingesetz.
-
Lass dich inspirierenUnser Beispiel-Projekt auf GitHub ist vielleicht auch für Dein Projekt eine nützliche Inspirationsquelle.
Das Wichtigste in Kürze
Applikations-Architektur in Go
Eine passende Architektur zu finden ist für die meisten Go-Einsteiger das grösste Problem. Von Frameworks wie Laravel oder Ruby on Rails sind wir es uns gewohnt, in einer fix vordefinierten Struktur zu arbeiten. Wird nun aber auf ein Framework verzichtet, müssen zahlreiche Entscheidungen zur Architektur selber getroffen werden.
Die richtige Architektur zu finden wird zusätzlich dadurch erschwert, dass in Go «Circular Dependencies» nicht erlaubt sind. Hängt also Package A von Package B ab, darf Package B keinerlei Abhängigkeiten von Package A haben.
Wir haben nach mehreren Iterationen unsere Struktur für Go-Applikationen gefunden. Ist diese perfekt? Keineswegs! Mit jeder zusätzlichen Anforderung muss die Struktur erneut evaluiert und womöglich auch angepasst werden. Bestätigt wurde unsere Architektur aber damit, dass wir die neue Version unserer CareSuite-Softwarelösung in den vergangenen Monaten ohne grössere Probleme darin umsetzen konnten.
Da es schwierig ist, alle Details der Applikation in einem Blog-Beitrag zusammenzufassen, haben wir ein Beispielprojekt mit der in diesem Beitrag beschriebenen Struktur auf GitHub veröffentlicht: https://github.com/OFFLINE-GmbH/go-webapp-example
Dieser Blog-Beitrag soll ergänzend zum Beispielprojekt eine grobe Übersicht bieten.
Unsere Inspiration
Unsere Architektur wurde von einigen Ressourcen inspiriert:
Für das Layout des Repositories verwenden wir das golang-standards Layout. Dieses Layout hat mindestens genau so viele Gegner wie Befürworter. Viele sagen, dass das Layout für die meisten Projekte ein «Overkill» ist. Für einfachere Projekte stimme ich dem zu. Unser CareSuite-Repository enthält jedoch unter anderem Ansible-Playbooks, Dockerfiles, GraphQL-Schemas, ein GraphQL-Server, Übersetzungsdateien, eine Vue-Applikation sowie Dokumentation-Websites für Integratoren und Endkunden. Alle diese Komponenten in einem Monorepo unterzubringen bedarf einem passenden Layout. Das golang-standards ist für unseren Anwendungsfall also perfekt geeignet.
Für die eigentliche Architektur des Backend-Servers liessen wir uns von Artikeln wie «How I write Go Http services after eight years», dem git-bug Projekt (für das GraphQL-Schema) und der Clean Architecture inspirieren.
Die «Clean Architecture» half uns besonders bei der Aufteilung der einzelnen Software-Komponenten. Die wichtigste Regel der «Clean Architecture» besagt, dass Abhängigkeiten im unten stehenden Schema immer nur nach innen verweisen dürfen. Befolgt man diese Regel, werden zirkuläre Abhängigkeiten in der eigenen Go-Applikation komplett vermieden.
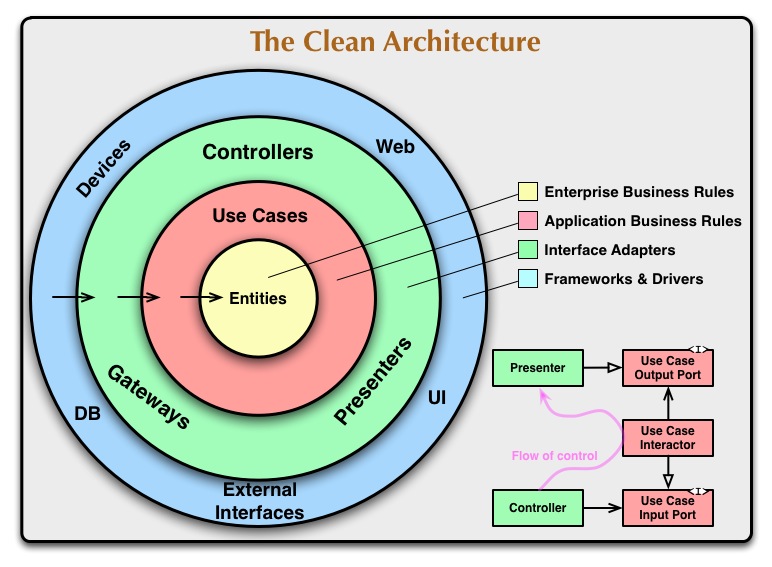
Entities
Um Entities (oder auch Models) im Projekt abzulegen, ohne zirkuläre Abhängigkeiten zu schaffen, verwenden wir ein entity-Package, auf dem alle «Models» definiert werden (die Mitte der «Clean Architecture»).
Dieses Package enthält keine Logik, sondern lediglich die für die Applikation relevanten Datenstrukturen. Da sich diese Entities im Zentrum der «Clean Architecture» befinden, können Sie überall in der Applikation verwendet werden, ohne dass zirkuläre Abhängigkeiten entstehen.
package entity
// Im entity Package wird lediglich die Struktur eines Users definiert
// Datenbank, Validierung, HTTP, usw. passieren ausserhalb.
type User struct {
ID int `json:"id"`
Name string `json:"name"`
Password string `json:"-"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
}Use Cases
Jede Entity erhält ihr eigenes Package im internal/pkg Verzeichnis. Darin enthalten sind wiederum ein «Store» (für den direkten Datenbankzugriff) sowie ein «Service» um die Datenbankzugriffe mit erweiterter Logik zu ergänzen. Store und Service stellen die zweite «Use Cases»-Ebene der Clean Architecture dar ‒ dies ist der einzige Ort, an dem Daten geladen und geschrieben werden.
Wir haben auf die Aufteilung in einzelne «Use Cases» verzichtet, da viele unserer Entities zum aktuellen Zeitpunkt nur die üblichen CRUD-Methoden besitzen. Bei Entities mit mehr Funktionalität können die Use Cases jedoch problemlos ergänzt werden.
Wir verwenden für das Zusammenspiel zwischen Store und Service eine Methode, die von Jon Calhoun's «Web Development with Go» Videoserie inspiriert ist: Im Store werden alle Datenbankabfragen platziert. Der Service enthält den Store als eingebettetes Feld. Dies erlaubt es uns, überall in der Applikation mit dem Service-Struct zu arbeiten und darauf gezielt weitere Logik um die Datenbankabfragen herum zu ergänzen. Weil der Store im Service eingebettet ist, stehen alle Methoden des Stores auf dem Service ebenfalls zur Verfügung.
package user
type Store struct {
db *db.Connection
}
// Der Store kümmert sich lediglich um die Datenbankabfragen.
// Weitere Logik wird im Service platziert.
func (s Store) Create(ctx context.Context, user *entity.User) (*entity.User, error) {
// Benutzer erstellen und zurückgeben
res, err := s.db.Exec(
"INSERT INTO users (name, password) VALUES (?, ?);",
user.Name,
user.Password,
)
return user, err
}
// Der Store wird im Service eingebettet.
type Service struct {
// Der Store ist eingebettet (das Feld hat keinen eigenen Namen)
// Somit sind alle Store Methoden auf dem Service aufrufbar.
*Store
}
// Beim Aufruf der «Create» Methode auf dem Service wird vorgängig das
// Passwort gehashed. Der Service ruft dann die Create-Methode
// des Stores auf.
func (s Service) Create(ctx context.Context, u *entity.User) (*entity.User, error) {
u, _ := hashPassword(u)
return s.Store.Create(ctx, u)
}
// Auf dem Service kann z. B. auch ideal eine Login-Methode platziert werden.
func (s Service) Login(ctx context.Context, username, password string) (*entity.User, error) {
u, _ := s.Store.FindByUsername(ctx, username)
err = bcrypt.CompareHashAndPassword([]byte(u.Password), []byte(password))
if err != nil {
return nil, entity.ErrUserInvalidPassword
}
s.Session.Put(ctx, "user_id", user.ID)
return user, nil
}Wir verzichten absichtlich darauf, unseren Datenbankzugriff über ein Interface zu abstrahieren. Zum einen ist dies nicht die Art und Weise, wie Interfaces in Go eingesetzt werden, zum anderen erhöht jede Abstraktion die Komplexität des Codes um ein Vielfaches.
Die Idee, dank einem Datenbank-Interface frei die darunterliegende Datenbank wechseln zu können (zum Beispiel von MySQL zu Postgres oder SQLite) ist unserer Ansicht nach ein Scheinargument. In realen Projekten wird die Datenbank nicht einfach so von heute auf morgen gewechselt. Auch die Verwendung von «in-memory Datenbanken» wie SQLite für die Ausführung von Testfällen, finden wir heikel. Datenbank-Interaktionen sollten als Integrationstests auf einer echten Datenbank ausgeführt werden. So decken die Tests auch alle Eigenheiten der verwendeten Datenbank ab.
Möchten wir dennoch ein Unit-Test ohne direkten Datenbank-Zugriff schreiben, können wir dies mit einem Interface im Konsumenten-Package lösen. Darauf werden lediglich die Store-Methoden definiert, die effektiv benötigt werden:
type userFinder interface {
// Alles, was wir brauchen, ist die FindByUsername Methode.
FindByUsername(username string) (*entity.User, error)
}
// Dank des userFinder Interfaces können wir einen
// echten Store oder eine «Mock-Implementierung» für Tests verwenden.
func SearchUser(finder userFinder, username string) (*entity.User, error) {
user, _ := finder.FindByUsername(username)
}
// MockDB gibt beim Aufruf von FindByUsername immer einen User zurück.
type mockDB struct {}
func (mockDB) FindByUsername(username string) (*entity.User, error) {
return &entity.User{Username: "admin"}, nil
}
// Ein Unit-Test ohne Datenbankanbindung ist jetzt einfach umzusetzen.
func TestSearchUser(t *testing.T) {
db := &mockDB{}
// Für den Test übergeben wir eine mockDB an die Funktion.
// Im produktiven Code wäre dies ein Store mit der
// FindByUsername Methode, die das Interface implizit erfüllt.
user, _ := SearchUser(db, "admin")
assert.Equals(t, "admin", user.Username)
}Controller
Auf der dritten «Controllers» Ebene steht für uns der GraphQL-Server. Diesen generieren wir mit dem gqlgen-Package. Dieses generiert basierend auf einem vordefinierten GraphQL-Schema einen GraphQL-Server in Go. Die einzige Arbeit, die für uns bleibt, ist die Implementierung der einzelnen Endpunkte.
Dank der bestehenden Aufteilung in Store und Service gibt es an dieser Stelle kaum noch Logik. Die meisten Queries können nach der Validierung des Inputs direkt an den Service weitergeleitet werden, wo Speicherung und Error-Handling stattfinden.
func (r *queryResolver) CreateUser(ctx context.Context, input *entity.User) (*entity.User, error) {
// Inputdaten validieren
if err := user.ValidateCreateRequest(input); err != nil {
return nil, err
}
// Wenn alles OK ist, den Input an den Service weitergeben.
return r.Services.User.Create(ctx, input)
}Externe Abhängigkeiten
Natürlich kommt auch unsere Applikation nicht komplett ohne Code von Drittanbietern aus. Wir nutzen beispielsweise das sqlx-Package für den Datenbankzugriff, casbin für die Authorization von Benutzerkonten oder chi als HTTP-Router.
Wir isolieren alle diese Abhängigkeiten im pkg-Verzeichnis, wo wir sie in eigene Packages verpacken. Hierbei gilt: Keine externe Abhängigkeit darf ausserhalb des pkg-Verzeichnisses verwendet werden. Dies sorgt einerseits für mehr Übersicht über die verwendeten Packages von Drittanbietern und ermöglicht es, diese relativ einfach auszutauschen, falls sich die Anforderungen an die Applikation ändern.
Das «Verpacken» der Abhängigkeit ist meist sehr einfach zu erledigen. Die API der Abhängigkeit kann 1:1 kopiert werden oder an die eigenen Bedürfnisse angepasst werden. Weiterer Bonus: Diese Methode ermöglicht es, weitere Funktionalität zu ergänzen. Wir fügen so z. B. ein einfaches Query-Log zu sqlx hinzu:
package db
type Connection struct {
*sqlx.DB
log log.Logger
}
func New(logger log.Logger) *Connection { // ... }
// Query ruft einfach die originale sqlx Methode auf.
// Zusätzlich wird aber auch gleich jede Query geloggt.
func (c *Connection) Query(query string, args ...interface{}) (*Rows, error) {
defer logQueryWithArgs(c.log, time.Now(), query, args)
// Der Aufruf wird direkt an sqlx weitergegeben.
rows, err := c.DB.Query(query, args...)
return &Rows{rows}, err
}
// logQueryWithArgs loggt die Query, deren Argumente sowie die Ausführungszeit.
func logQueryWithArgs(logger log.Logger, start time.Time, query string, args []interface{}) {
// Query-Platzhalter mit Argumenten ersetzen (für bessere Lesbarkeit im Log).
query = strings.ReplaceAll(query, "?", "%v")
query = fmt.Sprintf(query, args...)
duration := time.Since(start)
entry := logger.WithFields(log.Fields{"time": duration.String()})
// Langsame Queries werden als Warnings geloggt.
if duration > 100*time.Millisecond {
entry.Warnln(query)
} else {
entry.Traceln(query)
}
}Frontend
Das Frontend setzen wir bevorzugt in Vue.js um. Für die Kommunikation mit dem GraphQL-Server verwenden wir die vue-apollo Bibliothek.
Unser Tipp: Wir schreiben die einzelnen Vue-Komponenten in TypeScript. Zudem verwenden wir die graphql-codegen Bibliothek. Diese generiert basierend auf unserem GraphQL-Schema alle benötigten TypeScript-Typen. Somit ist die komplette Kommunikation zwischen Frontend und Backend typisiert. Wir sehen also bereits beim Erstellen eines GraphQL-Requests in der IDE, welche Felder benötigt werden, oder wo falsche Daten mitgesendet werden. Dies deckt die allermeisten Fehler im Zusammenhang mit GraphQL noch vor der Ausführung im Browser auf. Zudem ist die Autovervollständigung, die so entsteht, eine enorme Arbeitserleichterung.
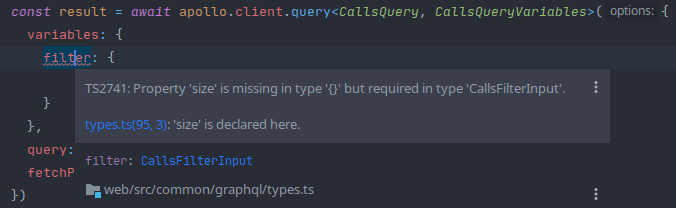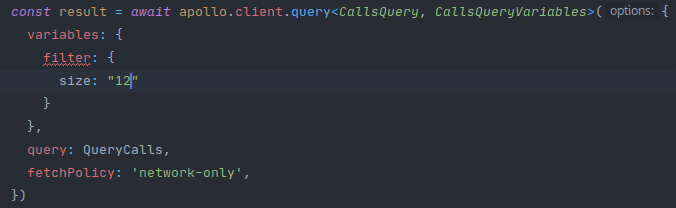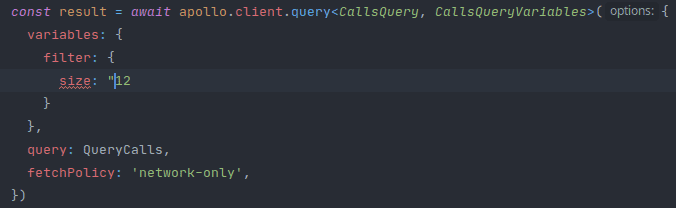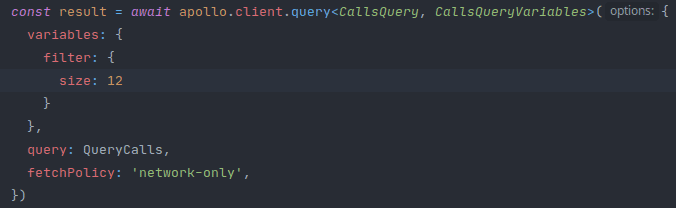
Und noch vieles, vieles mehr...
Für unsere Applikation benötigten wir noch zahlreiche weitere Funktionen wie Hintergrundprozesse, Audit Logs, Datenbank-Migrationen, Update-Routinen, Mehrsprachigkeit, Datenseeder, Websockets oder einen StatsD-Client.
Wer die Details zu diesen Funktionen selber erkunden möchte, findet sie alle auf GitHub: https://github.com/OFFLINE-GmbH/go-webapp-example

Tutorials, Informationen und Gedanken zur Go-Programmiersprache.
